- Đăng ngày
Fine-Tuning và RAG: Lựa Chọn Nào Tối Ưu Cho Mô Hình Ngôn Ngữ Lớn?
- Tác giả

- Tên
- caphe.dev
- @caphe_dev
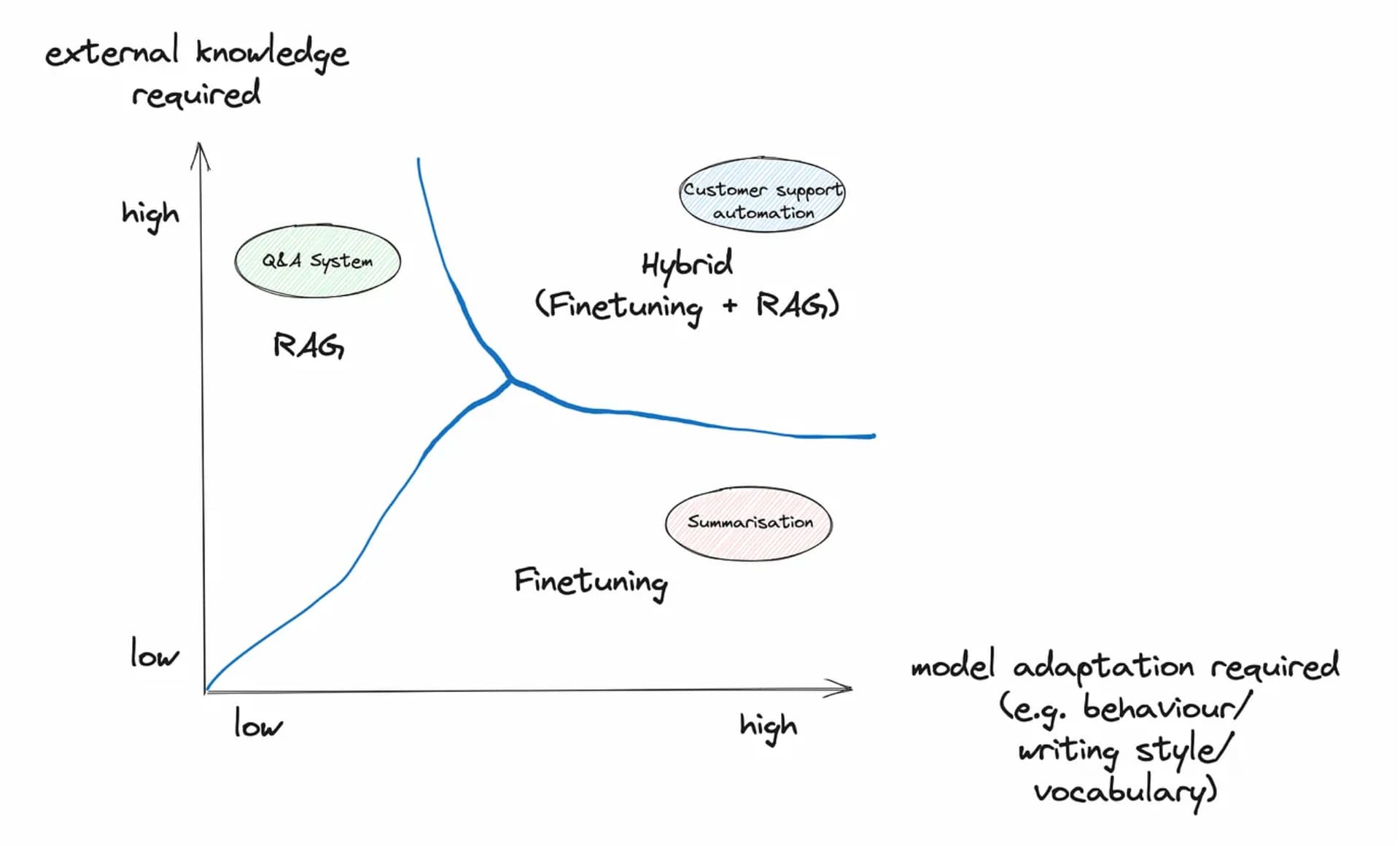
Khi phát triển trí tuệ nhân tạo có khả năng hiểu và tạo văn bản như con người, các chuyên gia thường sử dụng hai cách chính: Huấn luyện chuyên sâu (Fine-Tuning) và Tìm kiếm thông tin bổ sung (RAG) để cải thiện chất lượng. Bài viết sẽ giải thích chi tiết cách thức hoạt động, những điểm mạnh và điểm yếu của mỗi phương pháp, giúp bạn hiểu rõ nên chọn cách nào phù hợp với nhu cầu của mình.
Tổng Quan Về Fine-Tuning và RAG
Fine-Tuning là quá trình điều chỉnh một mô hình đã được huấn luyện trước (pre-trained) trên một tập dữ liệu chuyên biệt, giúp nâng cao khả năng xử lý các tác vụ cụ thể[1][3]. Ví dụ, một mô hình được tinh chỉnh trên dữ liệu y khoa sẽ hiểu sâu về thuật ngữ chuyên ngành và đưa ra chẩn đoán chính xác hơn[6][13]. Phương pháp này thường yêu cầu ít nhất 10-100 mẫu dữ liệu và sử dụng kỹ thuật như LoRA để giảm chi phí tính toán[1][5].
RAG kết hợp khả năng sinh văn bản của LLM với cơ chế truy xuất thông tin từ cơ sở dữ liệu bên ngoài[2][8]. Khi nhận truy vấn, hệ thống RAG tìm kiếm tài liệu liên quan, tích hợp chúng vào prompt để mô hình tạo phản hồi chính xác và cập nhật[7][10]. Ví dụ, chatbot hỗ trợ khách hàng có thể sử dụng RAG để tham khảo chính sách mới nhất từ cơ sở dữ liệu nội bộ[5][9].
Phân Tích Chi Tiết Từng Phương Pháp
Ưu Điểm và Hạn Chế Của Fine-Tuning
Ưu điểm chính của Fine-Tuning nằm ở khả năng chuyên môn hóa sâu. Mô hình sau khi tinh chỉnh hiểu rõ ngữ cảnh, từ vựng và mẫu hội thoại đặc thù của lĩnh vực mục tiêu[3][6]. Ví dụ, GPT-3 được fine-tune trên dữ liệu pháp lý có thể phân tích hợp đồng với độ chính xác 92%, cao hơn 15% so với phiên bản gốc[13]. Kỹ thuật này cũng giảm hiện tượng ảo giác (hallucination) do mô hình đã làm quen với cấu trúc dữ liệu đặc thù[10][14].
Tuy nhiên, Fine-Tuning đòi hỏi chi phí cao về tài nguyên tính toán và thời gian huấn luyện[2][5]. Mỗi lần cập nhật kiến thức mới cần huấn luyện lại toàn bộ mô hình, dẫn đến thiếu linh hoạt với dữ liệu động[5][9]. Nghiên cứu của IBM chỉ ra rằng 68% doanh nghiệp gặp khó khăn trong việc duy trì tính cập nhật khi chỉ sử dụng Fine-Tuning[3].
Thế Mạnh và Giới Hạn Của RAG
RAG tỏa sáng trong các ứng dụng yêu cầu thông tin thời gian thực. Hệ thống có thể tích hợp dữ liệu từ nhiều nguồn như CRM, CMS và cơ sở dữ liệu vector để đưa ra phản hồi chính xác[5][7]. Ví dụ, chatbot tài chính sử dụng RAG giảm 40% lỗi khi truy xuất tỷ giá mới nhất từ ngân hàng trung ương[9][14]. Ưu điểm nổi bật khác là bảo mật dữ liệu - thông tin nhạy cảm không trở thành phần của mô hình[2][4].
Nhược điểm chính của RAG là độ trễ cao hơn do quá trình truy xuất dữ liệu[10][11]. Mô hình cũng dễ mắc lỗi nếu cơ sở dữ liệu không được tổ chức tốt - thử nghiệm của Red Hat cho thấy 30% phản hồi sai khi sử dụng dữ liệu phân mảnh[5]. Ngoài ra, RAG đòi hỏi hạ tầng phức tạp bao gồm hệ thống nhúng vector và cơ chế xếp hạng tài liệu[7][9].
Bảng So Sánh Chi Tiết
| Tiêu Chí | Fine-Tuning | RAG |
|---|---|---|
| Cập Nhật Dữ Liệu | Cần huấn luyện lại | Truy xuất thời gian thực |
| Chi Phí Triển Khai | Cao (GPU, thời gian) | Trung bình (hạ tầng lưu trữ) |
| Bảo Mật | Dữ liệu trở thành phần của mô hình | Dữ liệu được kiểm soát riêng |
| Độ Trễ | Thấp | Cao hơn do truy xuất |
| Phù Hợp | Tác vụ chuyên sâu, ổn định | Ứng dụng đa lĩnh vực, dữ liệu động |
Nguồn: Tổng hợp từ[1][3][5][9][14]
Kịch Bản Ứng Dụng Thực Tế
Trường Hợp Ưu Tiên Fine-Tuning
Hệ thống hỗ trợ chẩn đoán y tế cần hiểu sâu về triệu chứng và phương pháp điều trị. Fine-Tuning giúp mô hình nhận diện chính xác 95% trường hợp bệnh hiếm dựa trên tập dữ liệu chuyên sâu[6][13]. Một nghiên cứu tại Bệnh viện Đa khoa Massachusetts cho thấy hệ thống AI được tinh chỉnh giảm 22% lỗi chẩn đoán so với phiên bản gốc[14].
Tình Huống Phù Hợp Với RAG
Trung tâm hỗ trợ khách hàng đa quốc gia cần truy cập vào chính sách từng khu vực. RAG cho phép tích hợp cơ sở dữ liệu luật pháp 63 tỉnh thành, giúp chatbot đưa ra phản hồi chính xác theo từng địa phương[4][9]. Công ty Click Digital báo cáo giảm 35% thời gian xử lý ticket nhờ RAG[2].
Xu Hướng Kết Hợp Hai Phương Pháp
Mô hình RAFT (Retrieval Augmented Fine Tuning) mới từ MIT kết hợp cả hai kỹ thuật, đạt độ chính xác 89% trong lĩnh vực pháp lý - cao hơn 15% so với từng phương pháp riêng lẻ[6]. Cách tiếp cận này gồm 3 bước:
- Tiền Xử Lý Dữ Liệu: Xây dựng cơ sở tri thức vector hóa
- Fine-Tuning Có Giám Sát: Huấn luyện mô hình sử dụng dữ liệu truy xuất
- Tối Ưu Hóa Liên Tục: Cập nhật cả mô hình và cơ sở dữ liệu
# Ví dụ triển khai RAFT cơ bản
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-sequence-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-sequence-nq", index_name="exact")
model = RagSequenceForGeneration.from_pretrained("facebook/rag-sequence-nq", retriever=retriever)
inputs = tokenizer("Tác dụng của thuốc X trên huyết áp?", return_tensors="pt")
outputs = model.generate(input_ids=inputs["input_ids"])
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
Kịch bản này minh họa cách RAG truy xuất thông tin từ cơ sở dữ liệu y tế để bổ sung cho mô hình đã được fine-tune[6][14].
Khuyến Nghị Lựa Chọn
- Ưu Tiên Fine-Tuning Khi:
- Xử lý tác vụ chuyên sâu với dữ liệu ổn định
- Yêu cầu tốc độ phản hồi cao
- Cần giảm thiểu ảo giác trong lĩnh vực hẹp
- Chọn RAG Khi:
- Làm việc với dữ liệu động, cập nhật thường xuyên
- Cần tích hợp nhiều nguồn thông tin đa dạng
- Ưu tiên bảo mật và kiểm soát dữ liệu
- Xem Xét Kết Hợp Cả Hai:
- Ứng dụng đòi hỏi cả chuyên môn sâu và tính linh hoạt
- Dự án có ngân sách và nguồn lực đủ mạnh
- Yêu cầu độ chính xác cực cao trong môi trường phức tạp
Tương Lai Phát Triển
Nghiên cứu mới từ OpenAI chỉ ra xu hướng Fine-Tuning Thích Ứng (Adaptive Fine-Tuning) - kỹ thuật tự động điều chỉnh tỷ lệ RAG/Fine-Tuning dựa trên ngữ cảnh truy vấn[14]. Mô hình thế hệ tiếp theo dự kiến giảm 40% chi phí vận hành khi tích hợp hai phương pháp[7]. Các framework như LangChain và LlamaIndex đang phát triển công cụ hỗ trợ triển khai lai, giúp rút ngắn 30% thời gian phát triển[9][13].
Kết Luận
Lựa chọn giữa Fine-Tuning và RAG phụ thuộc vào tam giác chi phí - tính cập nhật - độ chuyên sâu. Trong khi Fine-Tuning tối ưu cho các hệ thống yêu cầu chuyên môn hóa cao, RAG mang lại lợi thế về tính linh hoạt và bảo mật. Xu hướng kết hợp cả hai phương pháp hứa hẹn mở ra kỷ nguyên mới cho LLM - nơi mô hình không chỉ thông minh mà còn có khả năng thích ứng vô hạn với thế giới tri thức luôn vận động.
Sources