- Published on
Fine-Tuning and RAG: Which is the Optimal Choice for Large Language Models?
- Authors

- Name
- caphe.dev
- @caphe_dev
When developing artificial intelligence capable of understanding and generating text like humans, experts often use two main approaches: Fine-Tuning and Retrieval-Augmented Generation (RAG) to improve quality. This article will explain in detail how each method works, its strengths and weaknesses, helping you understand which approach is suitable for your needs.
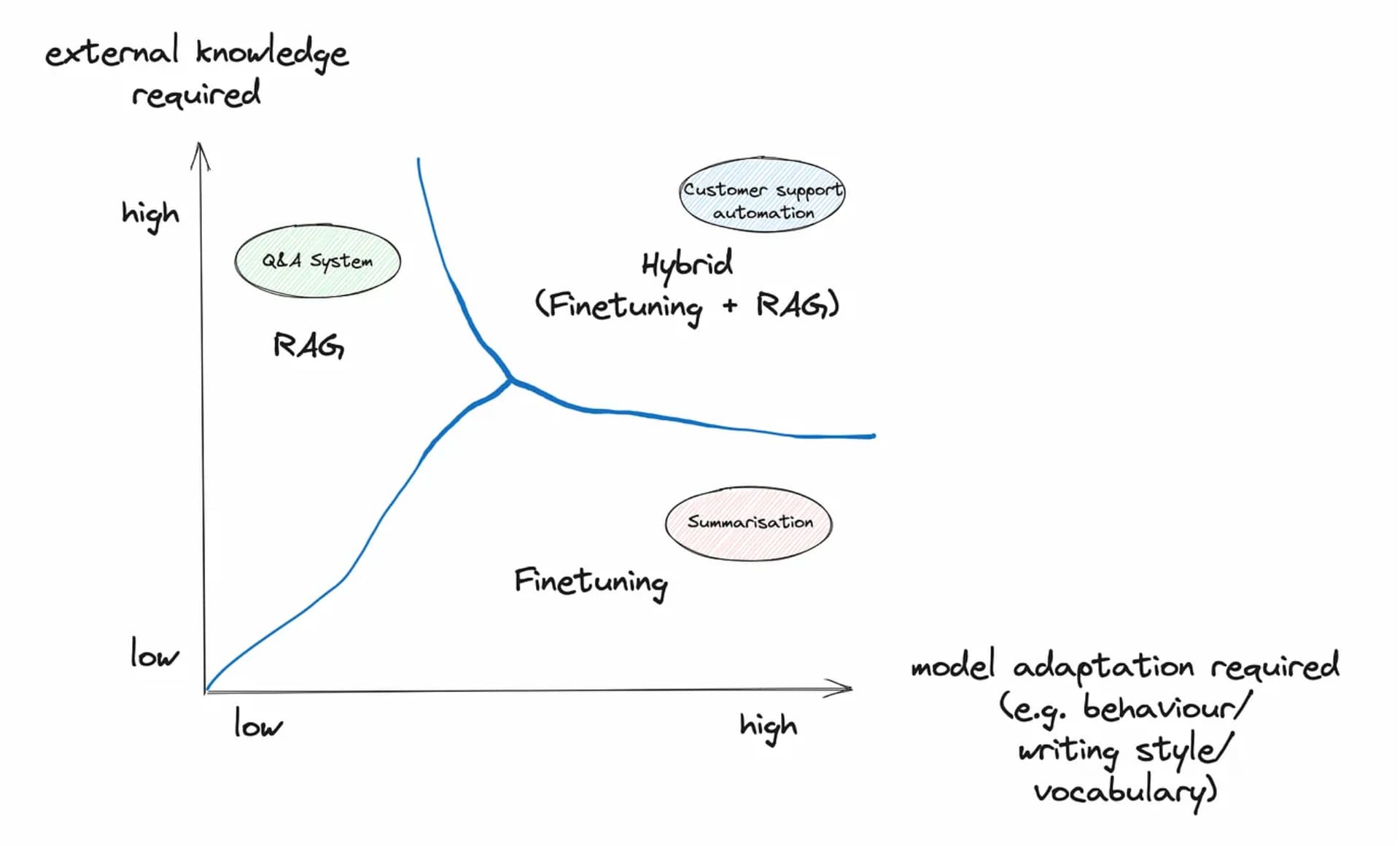
Overview of Fine-Tuning and RAG
Fine-Tuning is the process of adjusting a pre-trained model on a specialized dataset, enhancing its ability to handle specific tasks[1][3]. For example, a model fine-tuned on medical data will have a deeper understanding of specialized terminology and provide more accurate diagnoses[6][13]. This method typically requires at least 10-100 data samples and employs techniques like LoRA to reduce computational costs[1][5].
RAG combines the text generation capabilities of LLMs with an information retrieval mechanism from external databases[2][8]. When receiving a query, the RAG system searches for relevant documents, integrates them into the prompt, allowing the model to generate accurate and updated responses[7][10]. For instance, a customer support chatbot can use RAG to reference the latest policies from an internal database[5][9].
Detailed Analysis of Each Method
Advantages and Limitations of Fine-Tuning
The main advantage of Fine-Tuning lies in its ability to deeply specialize. The model after fine-tuning understands the context, vocabulary, and specific dialogue patterns of the target domain[3][6]. For example, GPT-3 fine-tuned on legal data can analyze contracts with 92% accuracy, 15% higher than the original version[13]. This technique also reduces hallucination since the model becomes familiar with the specific data structure[10][14].
However, Fine-Tuning requires high costs in computational resources and training time[2][5]. Each time new knowledge is updated, the entire model needs to be retrained, leading to lack of flexibility with dynamic data[5][9]. Research from IBM indicates that 68% of businesses struggle to maintain up-to-date information when relying solely on Fine-Tuning[3].
Strengths and Limitations of RAG
RAG shines in applications requiring real-time information. The system can integrate data from various sources such as CRM, CMS, and vector databases to provide accurate responses[5][7]. For example, a financial chatbot using RAG reduces errors by 40% when retrieving the latest exchange rates from the central bank[9][14]. Another notable advantage is data security - sensitive information does not become part of the model[2][4].
The main drawback of RAG is higher latency due to the data retrieval process[10][11]. The model is also prone to errors if the database is not well-organized - tests by Red Hat showed a 30% error rate when using fragmented data[5]. Additionally, RAG requires complex infrastructure including vector embedding systems and document ranking mechanisms[7][9].
Detailed Comparison Table
| Criteria | Fine-Tuning | RAG |
|---|---|---|
| Data Update | Requires retraining | Real-time retrieval |
| Deployment Cost | High (GPU, time) | Average (storage infrastructure) |
| Security | Data becomes part of the model | Data is kept separate |
| Latency | Low | Higher due to retrieval |
| Suitable For | Deep, stable tasks | Multi-domain applications, dynamic data |
Sources: Compiled from[1][3][5][9][14]
Real-World Application Scenarios
Case Favoring Fine-Tuning
A medical diagnosis support system needs to deeply understand symptoms and treatment methods. Fine-Tuning helps the model accurately identify 95% of rare disease cases based on a specialized dataset[6][13]. A study at Massachusetts General Hospital found that the AI system was fine-tuned to reduce diagnostic errors by 22% compared to the original version[14].
Situation Suitable for RAG
A multinational customer support center needs access to region-specific policies. RAG allows integration of legal databases from 63 provinces, enabling the chatbot to provide accurate responses according to local regulations[4][9]. Click Digital reported a 35% reduction in ticket processing time thanks to RAG[2].
Trends in Combining Both Methods
The new RAFT (Retrieval Augmented Fine Tuning) model from MIT combines both techniques, achieving 89% accuracy in the legal field - 15% higher than either method alone[6]. This approach consists of three steps:
- Data Preprocessing: Building a vectorized knowledge base
- Supervised Fine-Tuning: Training the model using retrieved data
- Continuous Optimization: Updating both the model and the database
# Example of basic RAFT implementation
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-sequence-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-sequence-nq", index_name="exact")
model = RagSequenceForGeneration.from_pretrained("facebook/rag-sequence-nq", retriever=retriever)
inputs = tokenizer("What is the effect of drug X on blood pressure?", return_tensors="pt")
outputs = model.generate(input_ids=inputs["input_ids"])
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
This scenario illustrates how RAG retrieves information from a medical database to supplement a fine-tuned model[6][14].
Recommendations for Choice
- Prioritize Fine-Tuning When:
- Handling deep tasks with stable data
- Requiring high response speed
- Needing to minimize hallucination in narrow domains
- Choose RAG When:
- Working with dynamic, frequently updated data
- Needing to integrate diverse information sources
- Prioritizing security and data control
- Consider Combining Both:
- Applications requiring both deep expertise and flexibility
- Projects with sufficient budget and resources
- Requiring extremely high accuracy in complex environments
Future Development
Recent research from OpenAI indicates a trend towards Adaptive Fine-Tuning - a technique that automatically adjusts the RAG/Fine-Tuning ratio based on query context[14]. Next-generation models are expected to reduce operational costs by 40% when integrating both methods[7]. Frameworks like LangChain and LlamaIndex are developing tools to support hybrid deployment, helping to shorten development time by 30%[9][13].
Conclusion
The choice between Fine-Tuning and RAG depends on the triangle of cost - update frequency - depth of expertise. While Fine-Tuning optimizes for systems requiring high specialization, RAG offers advantages in flexibility and security. The trend of combining both methods promises to usher in a new era for LLMs - where models are not only intelligent but also infinitely adaptable to the ever-evolving world of knowledge.
Sources